机器学习:决策树和组合算法
前言
以下是课程作业总结
问题来源:数据科学/方匡南编著,北京:电子工业出版社9.7.1/9.7.2习题
问题1:决策树
请分析R中ISLR包中的OJ(橘汁销售)数据集。该数据集包含了1070个顾客购买橙汁的记录。
- 用summary()函数查看数据基本信息,按7:3的比例划分训练集和测试集。
1 2 3 4 5 6 7 8 9 10
# 导入ISLR包 library(ISLR) # 查看数据基本信息 summary(OJ) # 设置随机种子以确保可重复性 set.seed(2333) # 划分训练集和测试集 train_index <- sample(1:nrow(OJ), 0.7 * nrow(OJ)) train_data <- OJ[train_index, ] test_data <- OJ[-train_index, ]
- 将purchase作为响应变量,其余变量作为预测变量,对训练集建立一棵树。用summary函数查看树的输出信息、训练错误率及树的终端节点个数分别是多少。
1 2 3 4 5 6
# 导入tree包 library(tree) # 建立一棵树 tree_model <- tree(Purchase ~ ., data = train_data) # 查看树的输出信息 summary(tree_model)
可看到输出信息:
1 2 3 4 5 6 7
Classification tree: tree(formula = Purchase ~ ., data = train_data) Variables actually used in tree construction: [1] "LoyalCH" "PriceDiff" "StoreID" "ListPriceDiff" Number of terminal nodes: 8 Residual mean deviance: 0.7527 = 557.7 / 741 Misclassification error rate: 0.1749 = 131 / 749
训练错误率约为0.1749,树的终端节点个数为8.
- 画出所建立的树并解释结果
1 2
plot(tree_model) text(tree_model, pretty=0)
输出图像:
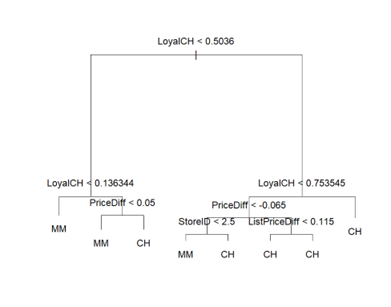
- 预测测试数据的响应值,并计算测试错误率
1 2 3 4
# 预测测试数据的响应值 test_pred <- predict(tree_model, test_data,type="class") # 计算测试错误率 table(test_pred, test_data $ Purchase)
输出结果:
1 2 3 4 5
test_pred CH MM CH 176 55 MM 13 77 > (176+77)/(176+55+13+77) [1] 0.788162
结果显示,该模型预测准确率约为78.82%
- 对树进行剪枝,用cv.tree()函数在训练集上确定最优的树。并画出错误率对size的函数。则建立一棵含5个终端节点的树。
1 2 3 4 5
# 进行树的剪枝 cv_tree <- cv.tree(tree_model,FUN = prune.misclass) cv_tree # 画出错误率对size的函数图形 plot(cv_tree$size, cv_tree$dev, type = "b", xlab = "Size", ylab = "Deviance")
输出结果:
1 2 3 4 5 6 7 8 9 10
$size [1] 8 7 5 4 2 1 $dev [1] 141 140 160 164 165 285 $k [1] -Inf 0 3 4 5 134 $method [1] "misclass" attr(,"class") [1] "prune" "tree.sequence"
从上述数据和图像发现,当终端结点为7时,错误率最低,误差为140。
问题2:组合模型分析
- 根据ISLR包中的Default数据集:p=100,n=100.将数据集按照6:4的比例划分训练集和测试集,分别利用决策树、随机森林、Adaboost、Adaboost和logistic回归对训练集构建模型,利用测试集对所构建的模型进行测试。比较这几个模型的训练集预测准确率及测试集的预测准确率。
导入包和划分数据集:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
# 导入ISLR包 library(ISLR) # 设置随机种子以确保可重复性 set.seed(233) # 加载所需的包 library(tree) library(randomForest) library(gbm) library(xgboost) library(pROC) # 加载Default数据集 data(Default) # 划分训练集和测试集 train_index <- sample(1:nrow(Default), 0.6 * nrow(Default)) train_data <- Default[train_index, ] test_data <- Default[-train_index, ]
决策树:
1
2
3
4
5
6
7
# 决策树模型
tree_model <- tree(default ~ ., data = train_data)
tree_train_pred <- predict(tree_model, train_data,type="class")
tree_test_pred <- predict(tree_model, test_data,type="class")
table(tree_train_pred, train_data$default)
table(tree_test_pred, test_data$default)
随机森林
1
2
3
4
5
6
7
# 随机森林模型
rf_model <- randomForest(default ~ ., data = train_data, importance=TRUE)
rf_train_pred <- predict(rf_model, train_data, type="class")
rf_test_pred <- predict(rf_model, test_data, type="class")
table(rf_train_pred, train_data$default)
table(rf_test_pred, test_data$default)
Adaboost
对于Adaboost模型,先将非数值项编码为数字,然后我们取n.trees=5000和interaction.depth=4作限制,阈值取0.5,
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 将非数值项转换为0或1
train.num <- train_data
test.num <- test_data
train.num$default<-as.numeric(train_data$default) - 1
train.num$student<-as.numeric(train_data$student) - 1
test.num$default<-as.numeric(test_data$default) - 1
test.num$student<-as.numeric(test_data$student) - 1
adaboost_model <- gbm(default ~ ., data = train.num, distribution = "adaboost",n.trees = 5000,interaction.depth = 4)
summary(adaboost_model)
adaboost_train_pred <- predict(adaboost_model, train.num, n.trees = 5000,type="response")
adaboost_train_pred <- ifelse(adaboost_train_pred > 0.5, 1, 0)
adaboost_test_pred <- predict(adaboost_model, test.num, n.trees = 5000,type="response")
adaboost_test_pred <- ifelse(adaboost_test_pred > 0.5, 1, 0)
table(adaboost_train_pred, train.num$default)
table(adaboost_test_pred, test.num$default)
XGboost
此处代码的计算过程应有误,因为ROC并不正常
1
2
3
4
5
6
7
8
9
10
11
12
# XGBoost模型
xgtrain_s <-Matrix::sparse.model.matrix(default~.-1, data = train_data)
xgtest_s <-Matrix::sparse.model.matrix(default~.-1, data = test_data)
dtrain <- xgb.DMatrix(data = xgtrain_s,label = train_data$default)
dtest <- xgb.DMatrix(data = xgtest_s,label = test_data$default)
xgboost_model <- xgboost(data = dtrain, max.depth=10,min_child_weight=1,gamma=0.1,colsample_bytree=0.8,subsample=0.8,scale_pos_weight=1,eta=0.1,eval_metric="auc",nround=10000,silent=TRUE)
xgboost_train_pred <- predict(xgboost_model, dtrain)
xgboost_test_pred <- predict(xgboost_model, dtest)
table(as.numeric(xgboost_train_pred > 0.5), train_data$default)
table(as.numeric(xgboost_test_pred > 0.5), test_data$default)
logistic回归
1
2
3
4
5
6
7
8
# Logistic回归模型
logistic_model <- glm(default ~ ., data = train_data, family = "binomial")
logistic_train_pred <- predict(logistic_model, train_data, type = "response")
logistic_test_pred <- predict(logistic_model, test_data, type = "response")
logistic_train_pred <- ifelse(logistic_train_pred > 0.5, 1, 0)
logistic_test_pred <- ifelse(logistic_test_pred > 0.5, 1, 0)
table(logistic_train_pred, train_data$default)
table(logistic_test_pred, test_data$default)
利用ROC曲线比较模型的好坏,并计算模型的AUC值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
train_accuracy <- function(pred, actual) {
mean(pred == actual)
}
test_accuracy <- function(pred, actual) {
mean(pred == actual)
}
# 计算各模型的训练集和测试集预测准确率
# 计算各模型的ROC曲线和AUC值
train_accuracy <- function(pred, actual) {
mean(pred == actual)
}
test_accuracy <- function(pred, actual) {
mean(pred == actual)
}
train.num$default
models <- c("决策树", "随机森林", "Adaboost", "XGBoost", "Logistic回归")
train_acc <- c(train_accuracy(tree_train_pred, train_data$default),
train_accuracy(rf_train_pred, train_data$default),
train_accuracy(adaboost_train_pred, train.num$default),
train_accuracy(as.numeric(xgboost_train_pred > 0.5), train.num$default),
train_accuracy(logistic_train_pred, train.num$default))
test_acc <- c(test_accuracy(tree_test_pred, test_data$default),
test_accuracy(rf_test_pred, test_data$default),
test_accuracy(adaboost_test_pred, test.num$default),
test_accuracy(as.numeric(xgboost_test_pred > 0.5), test.num$default),
test_accuracy(logistic_test_pred, test.num$default))
result <- data.frame(Model = models, Train_Accuracy = train_acc, Test_Accuracy = test_acc)
result
# auc
roc_curve <- roc(test_data$default, as.numeric(tree_test_pred))
auc_tree <- auc(roc_curve)
roc_curve <- roc(test_data$default, as.numeric(rf_test_pred))
auc_rf <- auc(roc_curve)
roc_curve <- roc(test_data$default, as.numeric(adaboost_test_pred))
auc_adaboost <- auc(roc_curve)
roc_curve <- roc(test_data$default, as.numeric(xgboost_test_pred))
auc_xgboost <- auc(roc_curve)
roc_curve <- roc(test_data$default, as.numeric(logistic_test_pred))
auc_logistic <- auc(roc_curve)
# 打印结果
auc_result <- data.frame(Model = models, AUC = c(auc_tree, auc_rf, auc_adaboost, auc_xgboost, auc_logistic))
auc_result
最后输出结果是:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
> result
Model Train_Accuracy Test_Accuracy
1 决策树 0.9733333 0.97250
2 随机森林 0.9763333 0.97150
3 Adaboost 1.0000000 0.96600
4 XGBoost 0.0340000 0.03225
5 Logistic回归 0.9740000 0.97200
> auc_result
Model AUC
1 决策树 0.6598199
2 随机森林 0.6218352
3 Adaboost 0.6826892
4 XGBoost 0.8246152
5 Logistic回归 0.6445743
不要问为什么XGboost的ROC值怎么奇怪,因为就是错的
思考如何选择最优模型来预测
从roc和auc值综合考虑,Adaboost模型最优。
本文由作者按照 CC BY 4.0 进行授权